A Survey of Dynamic Array Structures
This is a more thorough coverage of one of the topics that came up in my recent BSC25 talk "Assuming As Much As Possible"
You use arrays all the time.
The number of elements they need is often determined at runtime.
There many different alternatives for representing these, with different characteristics. Let's discuss these.
Caveats
- This is written by someone who tries to avoid general purpose allocators, mostly using arenas instead. I may miss some subtleties of use with GP allocation.
- I am not perfectly representing the entire design space, but picking representative points. Let me know if you feel I missed any significant alternatives.
First... you may not actually need a fully-dynamic array, so let's start with some not-quite-dynamic options that may be useful if you can get away with them.
Statically fixed-size array

Even if you don't know the exact number of elements, you may be able to set a reasonable upper bound and keep arrays of that fixed length.
Pros
- Easy to reason about
- No dynamic allocation
- Can store inline in structures (0 indirection)
Cons
- If your number of elements is highly-variable, the number of array slots you waste ends up dominating the actually-used slots. i.e. they become very inefficient.
- Difficult to reason about if length is user-controlled (and you aren't able to limit them).
- Array size is fixed after init; if you don't account for enough elements your program you either need additional handling or you enter an invalid state.
Runtime fixed-size array

Maybe you don't know the length at compile time, but at runtime you can work out how big some variably-sized data is before you allocate, so you just allocate a fixed block on an arena somewhere.
Importantly the array doesn't grow (beyond some accounted-for factor) after the initial allocation.
There's a variant of this where you effectively do some variable-length work twice: one going through the motions but not doing anything with the data, just to determine the length, and then a second time after allocating where you actually put the data in-place.
This is functionally the same as the static variant. Typically this will use an extra indirection, however you can allocate a struct as a header immediately before a runtime-sized array, which is sometimes called a "struct hack". In this case the data is offset from the header rather than being a "real" pointer indirection.
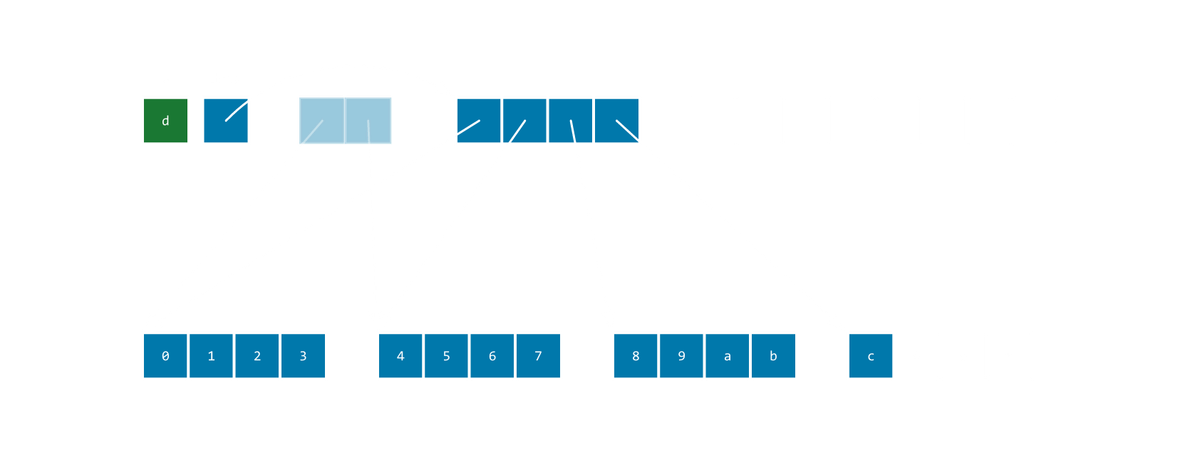
realloc-style double-and-copy array
Ok, now for the real dynamic arrays. We'll start with what is probably most developers' default structure.
Maintain a buffer with a particular capacity. When the length of the array exceeds the capacity you allocate a new buffer that is some factor larger than the original one (e.g. 2x the size, golden ratio times the size...), copy all the members over.
Variants of this include storing the capacity/length either at the start of the buffer or externally. If storing at the start, another variant is the STB-style header, where you store a pointer to the data, then do pointer arithmetic to find the metadata.
Pros
- Imposes minimal constraints; very general purpose
- Contiguous data
- "Amortized O(1) growth"
- Familiar to most developers
Cons
- Spiky latency: normally fine until you hit the growth point, then you have to allocate (possibly moderately expensive, depending on allocator) and copy potentially large amounts of data
- You can't take pointers to the array members that are stable across pushes to the array. You have to use indices instead.
- Either leaks memory or requires a moderately complex allocator
e.g. malloc/power-of-2 freelists/buddy allocator - These in-turn complicate use...
Aside 1: why is the allocation pattern a big deal?
When you resize the array, there is a choice about what to do with the old buffer. Options include:
A: Leak the memory, either indefinitely or until a later arena pop/clear.
B: free the buffer to your on-arena power-of-2 pool freelist.
C: free the buffer to a general-purpose allocator
A is nice and simple, but you approach 50% fragmentation as the best case occupancy. This is probably fine for short-lived or small arrays, but isn't great in the general case.
B uses the memory more efficiently, but if you're freeing to a list, you're almost certainly also allocating from them as well. This makes it non-obvious where the data for your next allocation will come from. If you're treating your arena as a stack, beware that pools and stacks interact badly unless you're very careful. (See Aside 3 for a similar error, bearing in mind that freeing involves appending data to a discontiguous list and is analogous to the array push there.)
C avoids you having to think about these things... but you're using a general-purpose allocator, so you miss out on all the arena advantages, it's also moderately slow and hard to reason about when you end up needing to.
Any non-trivial allocation seems to end up with treating the array as an invidual element, that you then have to individually free (unless you clear the entire freelist pool), negating the benefits of grouped lifetimes on an arena.
You can no longer do the really useful pattern of:
- Get current arena location
- Do a bunch of stuff that includes arbitrary allocation
- Pop arena back to initial location
Aside 2: what's wrong with using indices?
I'm not anti-index, they're better than pointers for a few particular use-cases (out-of-scope here). However, being forced to use them does come with some downsides:
- You need to provide some means of accessing the base of the array.
- You now have the potential to index into the wrong array, possibly an array of a different type.
- For a single array access you now have to provide 2 pieces of data instead of just 1 (e.g. in structs, parameter lists), which is sometimes a bit of a pain, but normally manageable.
- Indices in structs can't be auto-dereferenced by debuggers (without additional markup describing a base expression). This adds extra friction to following references.
- If you have nested arrays inside of arrays inside of arrays, all with unstable pointers, you need a piece of data for each step in this chain to stably & uniquely identify a leaf element. This becomes considerably annoying to write code for, and also uses a significant factor more memory if you need a lot of references to these leaf elements.
(I mention hitting this nested case in WhiteBox in the talk.)
Arena-backed array

Uses virtual memory tricks to reserve a very large contiguous address range that won't be backed by actual memory unless it's used.
This can take the form of either:
- An entire arena dedicated to one array, which is a special-case of:
- All pushes of members to this array are simplex (i.e. not interleaved with pushing anything else onto the arena), so they're always occurring at the end of an arena.
Pros
- Contiguous address space - easy to reason about
- Doesn't use memory that isn't required
Non-issues
- On 64-bit systems the address space is very large, so you're unlikely to run out
Cons
- Each arena needs to be freed individually, so you want a small, tractable number. This limits how many arrays you want to be fully backed by arenas.
- Avoiding interleaving is only practical in certain circumstances. You need as many arenas as you have interleaved pushes.
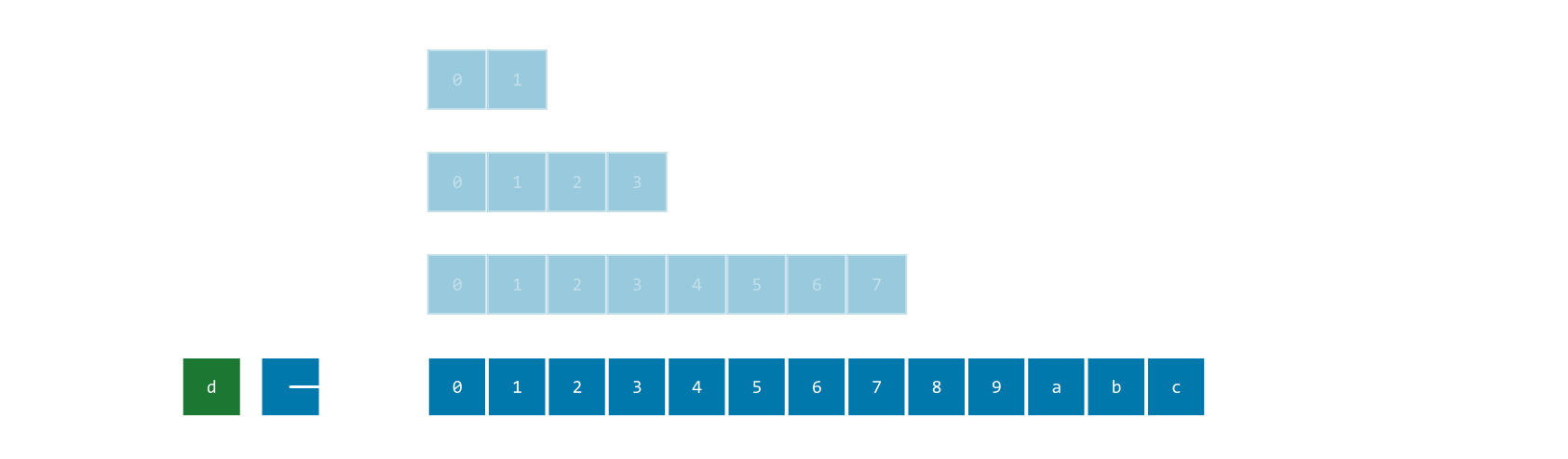
Chunk/Bucket arrays
Your array is effectively split into chunks of (typically) even size that contain the actual data.
You then add a layer of metadata: a separate array of pointers, pointing to the start of each subsequent block.
The chunks remain stable while the metadata moves around like a normal realloc array.
Pros
- Stable pointers
- No data copying required, leaving allocation as the main source of latency spikes.
Non-issues
- It doesn't matter that the metadata is unstable because nothing outside the array needs to take pointers to it
- Contiguous data within chunks means that cache efficiency can stay high.
- Still has O(1) access to any of the members: just a divmod of the chunk size to determine which pointer & then the offset within the chunk.
(if you choose a power of 2 this becomes a shift and an AND, which are very cheap operations)
Cons
- O(N) metadata
- This basically inherits all of the issues of the
realloc-style array, but scaled down by the constant factor of the chunk size - As the elements are no longer contiguous you lose the ability to easily make subslices or determine the distance between 2 element pointers by simple subtraction.
- Although the pointer instability is a non-issue, the bookkeeping & allocator work for the metadata are non-trivial
- 2 levels of indirection: to the metadata, then through to the pointer chunks
Aside 3: who cares if the elements aren't contiguous?
When you have discontiguous chunks, you run into a few issues.
Slices
With contiguous arrays, you can make a {length, pointer} slice of arbitrary subsections of data with no allocation or extra work required.
Significantly, you can treat slices of the full structure or of any subsection equivalently.
Once you have chunks, unless you have a structure designed with this specifically in mind, you lose the ability to easily make slices. It's not just that you can't take a pointer + length because there may be a gap, although this is the first issue you hit. The presence of the chunks and the fact they have either assumed size or chunk-header size data makes it meaningfully different to point to an element at the start of the chunk or the end of the chunk.
You can always fall back to "full container structure (pointer/copy) + start & end indices", although this is a bit clunky.
Distances are no longer meaningful
With a simple array, you can subtract the pointer of one element from another to find the displacement/distance between the 2. The most obvious place this is useful is that you can subtract the base from an arbitrary member to find its index.
This does not apply if there are gaps in the middle of the array. It's not that it's impossible to compute an index from a pointer, but it's now a thing, it needs to look at metadata, probably with loops and memory indirection and function calls... not just a trivial subtraction.
New opportunity for error
This is possibly one of the few error modes that are more likely with an arena than with general-purpose memory management. The issue arises when you're using the arena as a stack and aren't sufficiently careful about not interleaving array pushes & accesses with arena pops. This is probably best illustrated with an example:
DiscontiguousArray arr = {0};
for (int i = 0; i < n; ++i)
{
push_onto_arr(&arena, &arr, some_other_data[i]);
}
UPtr arena_checkpoint = arena_get_checkpoint(&arena);
// ...
push_onto_arr(&arena, &arr, more_data); // BAD
// ...
pop_to_checkpoint(&arena, arena_checkpoint);
Thing new_thing = arena_push_data(&arena, sizeof(thing), &thing); // CLOBBER
do_something_with_arr(&arr); // INVALID
The array now may have chunks that are not in the allocated memory of the arena, so new arena pushes can return that same memory to be overwritten for completely different purposes. This means that the last element could be corrupted. This is, in effect, a special case of use-after-free that the split structure enables. From the arena's perspective we're misusing its stack.
A hazard here is that this will fail inconsistently and potentially silently. There is only a visible error if pushing the member in the BAD line allocates a new chunk. If the chunk allocated before the checkpoint isn't full, then the new element goes into "safe" memory. Separately, if you don't push any other data and you don't invalidate the "freed" arena memory, you'll read it without issue... this time.
I don't want to overstate this: I think I've hit this error once, maybe twice, but it is something to be aware of. ASan poisoning or clearing popped arena memory to known-garbage data (e.g. memset(0xcc)) in debug mode will also make it loud in many cases.
Linked chunks
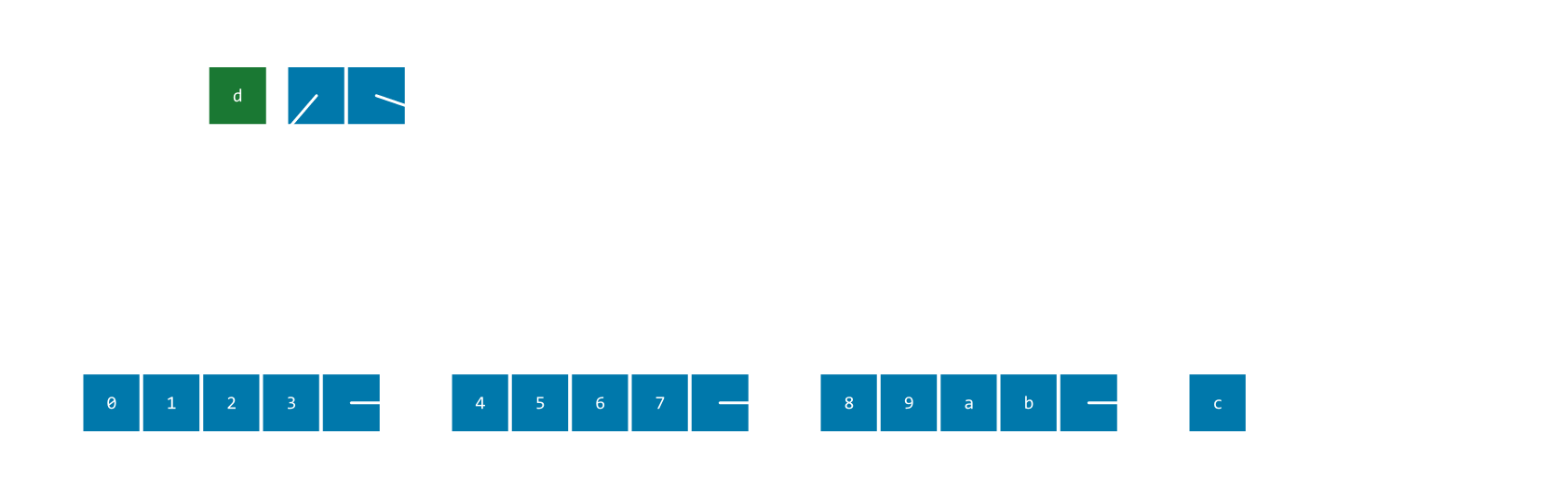
Keep pointers to just the first and last chunk, then have each chunk point to the one that comes after it. Chunk sizes could be fixed or dynamic, with a size header at the beginning of each chunk.
(Normal linked lists are a special-case of this where chunk_n == 1)
Pros
- Minimally-complicated bookkeeping structures or code
- Large enough chunks can provide reasonable cache usage
- Trivial to allocate on arenas
- Trivial iteration
Cons
- O(N) metadata
- O(N) random access
Good for traverse-only structures. (We use them for string lists in WhiteBox).
Tree
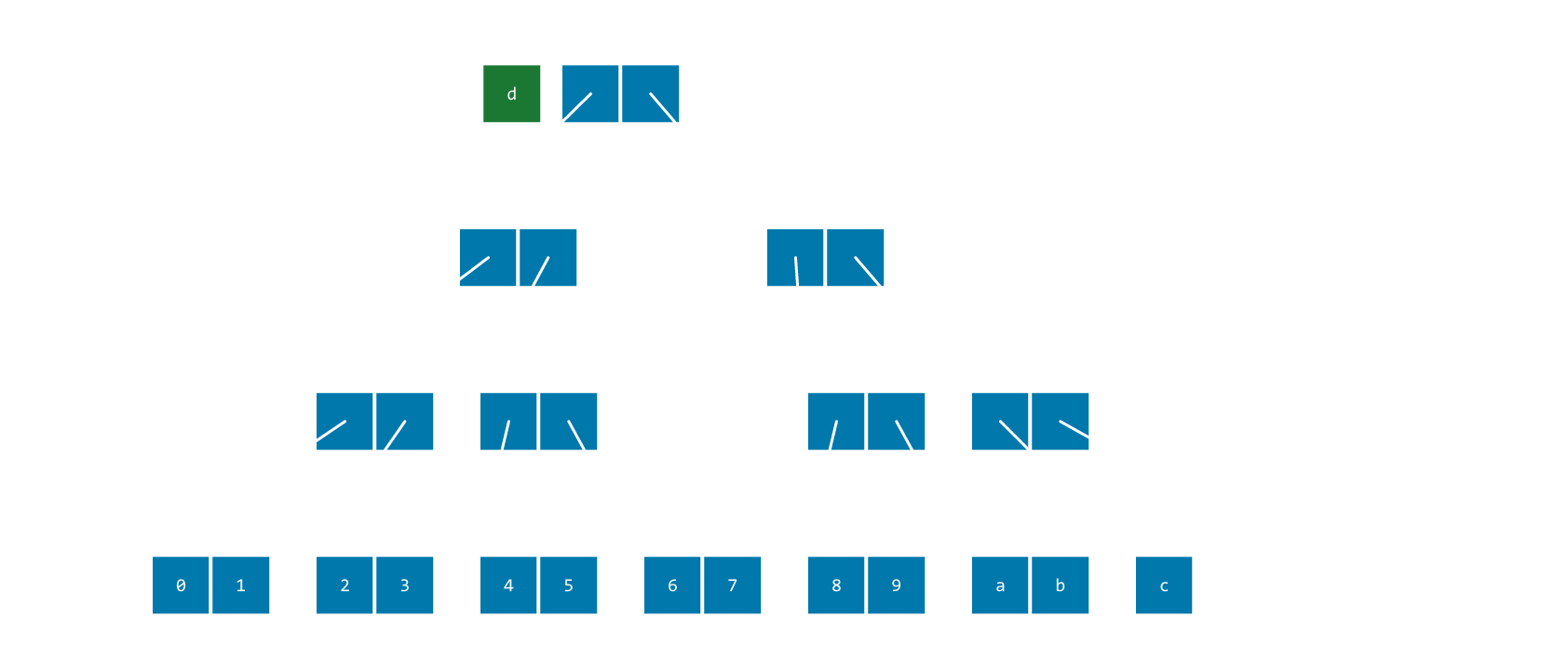
Taking the metadata layering of chunk arrays to its logical extent, and making it recursive.
There are many different implementations, and fully differentiating all the options is way out-of-scope here. They'll mostly have the same characteristics for our purposes here.
A couple of significant variants:
- All data in leaf nodes vs data in leaf AND inner nodes
- Fixed/variable branching factors (i.e. how many child nodes does each node have)
- All leaf nodes at the same depth vs variable-height subtrees.
- Skip lists are a notable oddity that are more like the linked chunks than the chunk array.
Pros
- Pretty good at everything: commonly O(log(N)) for most operations (read/write/insert/update/...)
- Can have holes in the middle of your index space if your members are sparse.
- Can use "structural sharing" to deduplicate data within or across arrays (if you can make assumptions about data immutability).
Cons
- Not great at anything
- Lots of indirection
- This can be reduced in some circumstances at the cost of complexity
- Design work required to be cache efficient
- Significant stored metadata
- Significant bookkeeping
- O(N) metadata
- Moderately complicated work for accessing/modifying/iterating
Exponential Array - Xar
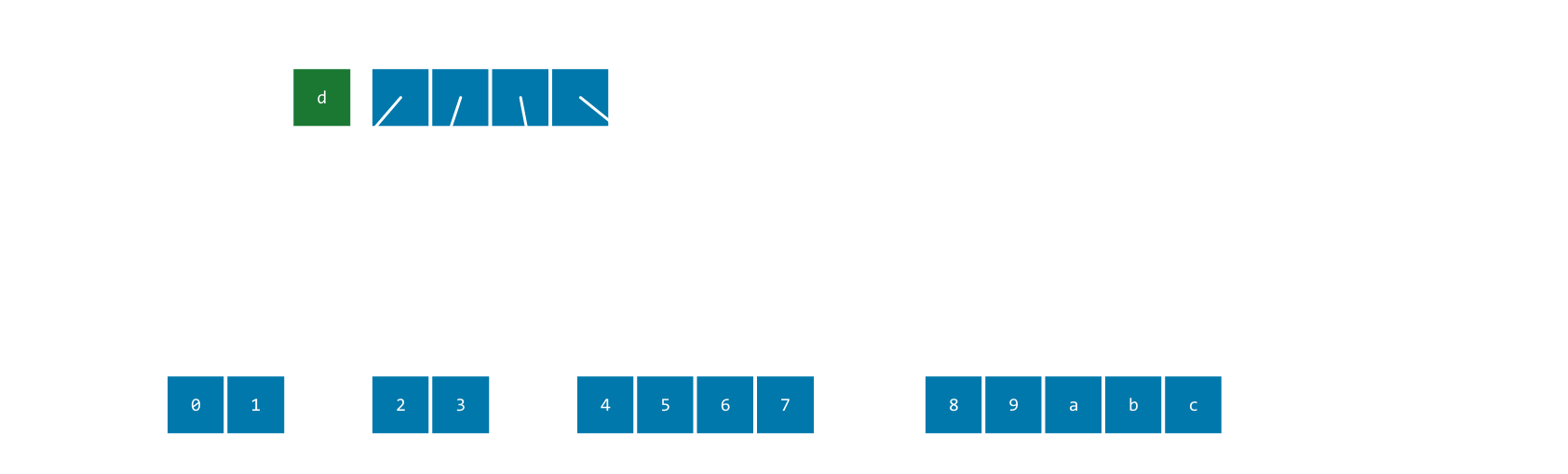
Use a fixed inline array of pointers to exponentially-growing chunks. (Watch for the upcoming article for a detailed explanation.)
Pros
- Minimal bookkeeping
- Only 1 level of indirection
- Trivial arena allocation pattern
- O(1)/fixed-size metadata
-
Useful information (e.g. max capacity, size of chunk X, ...) knowable at compile-time, which both makes it predictable as a user, and allows the compiler to perform optimizations relying on that information.
-
(In the theoretical general case it's O(log(N)), but it's easy to find a reasonable upper bound when you can double the capacity by adding a pointer)
-
- Minimal work on access (uses bitwise operations, no loops) & iteration.
Cons
- Each array struct is moderately large (~8-30 pointers). This is normally insignificant unless you have a huge number of these arrays that are close-to-empty.
- Inherits all discontiguous array issues (e.g. Aside 3)
- Can't really have holes: as the later chunks are the size of the sum of all preceding chunks, you can never be more than 50% sparse on memory for a given capacity.
(I implemented a slight generalization of this structure that treats subslices and the full data isomorphically - perhaps unsurprisingly called "Exponential Slice"/Xsl - but I haven't had the need to use it yet, and it comes with at least some extra complexity.)
This covers the span of the available options I am aware of. (If readers know of any viable alternatives that don't fit into the above archetypes I'd be interested to hear about them.)
Let's summarize these...
Comparison table
Columns are options, rows are consideratione:
| fixed array | 1-size allocation | realloc-style
| arena-backed | chunk arrays | chunked list | tree | xar | |
| |
|
|
 |
 |
|
|
|
|
| stable pointers | yes, unless you put them in an unstable structure | yes | no | yes | yes | yes | (depends, but probably) yes | yes |
| fully-contiguous data | yes | yes | yes | yes | no | no | no | no |
| fixed metadata | none | none | capacity | (piggybacks on arena's metadata) | capacity | head/tail pointers | root node | small chunk pointer array |
| variable bookkeeping/metadata | none | none | none | none | metadata pointer layer | list pointers | internal nodes | none |
| bookkeeping work | none | none | allocations + copies | none | metadata allocations + copies; chunk pointer targets | link pointer targets | multiple levels of node setup | chunk pointer targets |
| allocation | none/static | done once, but may have added complications by determining size | complex allocator (unless leaking) | piggybacks on arena (simple) | complex allocator for metadata (unless leaking) + simple allocation for chunks | simple | probably simple, but variations may add complexity (e.g. freelists) | simple |
| holes | no | no | no | no | yes | N/A / yes depending on interpretation | yes | technically yes, but not meaningfully |
| arena stack-friendliness/lifetime grouping | trivial | trivial | bad unless leaking old buffers | array per arena doesn't have any implicit lifetime grouping array at end of arena would be fine |
bad unless leaking old metadata buffers | trivial | good until you want to start freeing nodes | trivial |
| push interleaving | no issue | has to be manually multiplexed to different arenas | no issue | no issue | no issue | no issue | ||
| iteration | trivial | trivial | trivial | trivial | straightforward | trivial | requires additional structures to be efficient | straightforward |
| random access computation | trivial: base + offset | trivial: base + offset | trivial: base + offset | trivial: base + offset | straightforward: divmod/shift & AND | O(N) - often prohibitive | small loop | straightforward: bit manipulation |
| indirection for random access | 0 | 1 | 1 | 1 | 2 | N | log(N) | 1 |
Thanks to Judah Caruso for feedback on drafts of this post.